목표시스템
네이버의 급상승검색어에 접속하여 전체연령대의 실시간 랭킹 검색어를 가져와서
메신저로 공유하는 시스템을 만든다 (두레이)
결과물

네이버 급상승검색어
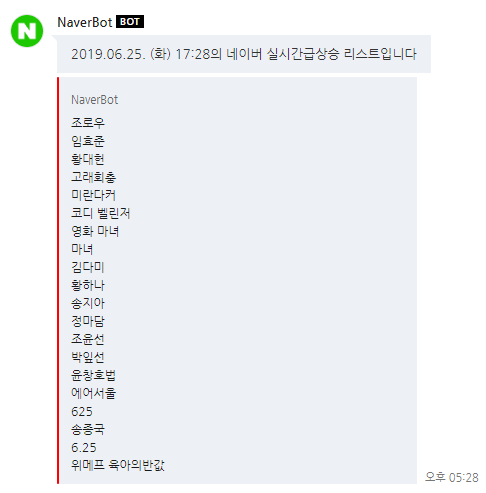
검색어내용을 두레이 메신저로 전달
개발환경 설정하기
서버리스 개발환경 설정은 이전의 포스팅 참고해주세요
package.json
node 8.10 을 사용하는 이유는 chrome-aws-lambda 가 아직 node 8.10 버전까지만 지원하기 때문입니다
node 버전 제한이 빠져있지만 node 8.10 버전을 사용해주세요
운영시 사용하는 모듈
· puppeteer : 구글의 크롬 핸들링 모듈
· chrome-aws-lambda : 람다가 사용할 크로미움 브라우저 모듈 (puppeteer 은 웹브라우저가 반드시 필요하다)
· request : 메신저의 webhook 으로 내용 (json 형태)을 보내기 위해서 사용
개발시 사용하는 모듈
· aws-sdk : aws javascript 모듈
· serverless-offline : offline 으로 람다 테스트용 모듈
옵션용 모듈
· mocha : 테스트 할 때 사용하는 모듈
· chai : mocha 와 한세트로 많이 사용하는 테스트용 모듈
· nyc : 코드 커버리지 확인할 때 사용하는 모듈
· eslint-config-prettier : 코드 깨끗하게 코딩하려고 사용하는 모듈
script 는
테스트 결과와 코드커버리지 확인용으로 2개의 명령어 설정해놓은 거 입니다
없어도 무방
주의사항
· 람다에 용량이 큰 파일을 올리는 것은 안좋습니다. 50MByte 초과는 안좋음
· puppeteer 이 사용하는 웹브라우저는 용량이 큽니다
· 그래서 chrome-aws-lambda 모듈을 사용합니다 (여기에 압축된 크로미움은 36MByte 정도임)
· chrome-aws-lambda 는 puppeteer 가 반드시 필요합니다 (puppeteer 로 웹브라우저로 핸들링하니깐)
· puppeteer 은 설치시에 300MByte 가 넘는 local-chromium 을 다운받아서 설치합니다
local-chromium 을 다운 받지 않는 방법은
1. npmrc 파일에 puppeteer_skip_chromium_download=true 를 넣어서 저장해두거나
2. puppeteer 대신에 puppeteer-core 를 설치하는 방법이 있습니다
여기서는 1번 .npmrc 파일에 puppeteer_skip_chromium_download=true 를 설정해서 다운받지 않는 방법으로 진행합니다
.npmrc 파일

같은 위치에 .npmrc 파일이 있으면 npm install 시에 .npmrc 내용을 참조해서 설치합니다
Step 1. .npmrc 파일과 package.json 파일을 생성하고 npm module 을 설치한다
npm install
Step 2. 서버리스 프레임워크 설정하기
serverless framework 가 global 로 설치 되어 있으면 yml 설정파일을 만듭니다
매번 반복하는 거니 이젠 serverless framework 는 기본으로 global 로 설치 되어 있겠지요
serverless.yml 파일내용
yml 설명
· custom 으로 변수를 정의해놓을 수 있습니다.
· 소스를 저장해놓은 bucket 명을 지정해 놓았습니다.
· 저는 stage 별로 다른 account 를 사용해서 별도로 소스 bucket 을 분리해놓은거니 일반적으로는 분리할 필요 없습니다
· 로그는 용량관리를 위해서14일만 저장해놓았습니다
· 소스를 bucket 에 저장시에 AES256 암호를 걸어놨습니다
· 다른 자원을 사용하지 않아서 추가적인 람다의 권한설정이 없습니다
· 혹시나 puppeteer 에 설치되어있는 크로미움 브라우저를 람다로 업로그 하는 것을 방지하려고 exclude 설정해놨습니다
· 람다 파일은 index.js 로 작성할 것이고 메인함수는 getNaverDataLab 이고 람다 표기 함수명도 동일하게 getNaverDataLab 입니다
· 람다 함수의 환경변수를 STAGE 1개를 설정했습니다
· 람다 함수의 메모리는 1.5GB , 타임아웃을 30초로 설정했습니다 (chrome-aws-lambda 모듈이 권장하는 메모리용량)
· Api gateway 를 통해서 람다함수가 실행될 수 있도록 http 이벤트를 걸었습니다
· api gateway 를 통해서 호출될 때 문제 없도록 CORS 적용해놨습니다
· 비용 추적을 위한 태그를 잔뜩 걸어놨습니다
· 복잡하게 AWS 자원을 사용하지않아서 x-ray 는 설정하지 않았습니다
Step 3. 네이버 급상승 검색어를 크롤링하는 소스를 개발합니다
Javascript 로 index.js 를 coding 합니다
설명
필요한 모듈을 읽어옵니다
const AWS = require("aws-sdk"); //AWS 자원사용에 필요
const chromium = require('chrome-aws-lambda'); //크로미움 웹브라우저와 puppeteer를 사용에 필요
const request = require('request'); //메신저 웹훅으로 request 날리기 위해서 필요
//웹훅을 보낼 웹훅 주소입니다
if(!process.env.DOORAYURL) process.env.DOORAYURL =
//크로미움에는 한글폰트가 없어서 한글이 깨지니 미리 한글폰트를 S3 에 저장해놓고 그걸로 폰트를 설정해줍니다
await chromium.font(KOREANFONT);
//response 헤더에 CORS 설정해줍니다
const response = {
headers: {
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Credentials": true
}
};
메인함수는 단순합니다
await chromium.font(KOREANFONT); //한글폰트 적용
browser = await chromium.puppeteer.launch(await this.getChromeBrowserArgument()); //크로미움 브라우저 띄우고
page = await browser.newPage(); //웹브라우저 페이지 만들고
let pageTitle = await gotoNaverRanking(page); //네이버랭킹페이지 접속하고
let searchDateTime = await getDateTime(page); //랭킹페이지의 날짜/시간을 가져오고
let searchKeys = await getSearchKeyList(page); //전체연령대의 검색순위 20개의 키워드 가져오고
let messageOptions = await makeMessage(searchKeys, searchDateTime); //메신저로 보낼 json 포멧 만들어서
let sendResult = await sendMessage(messageOptions); //메신저 웹훅으로 request 보냄
8개의 함수면 됩니다
Step 4. 로컬에서 테스트 해본다

윈도우 로컬 PC 에서 잘 작동하는 지 테스트 해봅니다
일단 localtest 폴더를 만들고 index.test.js 파일을 만듭니다
index.test.js 파일내용
별거 없어요
index.js 함수를 읽어와서 실행만 해주는 역할을 합니다
node localtest/index.test.js해당 명령어로 node 로 실행해봅니다
그러면 크롬브라우저가 실행되어 네이버 검색어를 가져오고


두레이 메신저로 요렇게 결과를 보내줍니다
Step 5. 서버리스 프레임워크로 배포한다
개발환경 배포
sls deploy -v --aws-profile AWS개발계정의사용자IAM계정Step 6. 배포된 람다를 확인한다
AWS 콘솔에서 람다함수 콘솔로 접근해서 테스트를 수행하면 확인할 수 있다 (람다함수가 입력받는 event 를 사용하지 않으니 빈값을 줘도 실행된다)

실행후에 로그는
클라우드워치 또는 sls logs 를 이용해서 확인한다
sls logs -t -f getNaverDataLab --aws-profile AWS사용자계정배포 이후에 나오는 api gateway 의 endpoints 로 접근해서 실행시킬 수 있습니다

배포에 대한 정보확인을 해볼 수 있습니다
sls info -v -f getNaverDataLab --aws-profile AWS사용자계정Step 7. 배포내용 삭제
cloudformation 을 통해서 serverless framework 로 설정한 모든 자원이 삭제된다
sls remove -v --aws-profile AWS개발계정의사용자IAM계정
아쉬운점
만들고 보니 네이버 급상승검색어 사이트가 datetime=2019-07-09T11:00:00
이라는 argument 로 이전 검색어도 제공해줍니다
datetime 을 이용해서 해당 시간대의 검색어 랭킹을 크롤링 해서
dynamoDB 에 테이블로 저장하는 것도 간단히 만들 수 있겠네요.
'IT > Serverless' 카테고리의 다른 글
| 서버리스 api gateway 도메인 적용 (0) | 2019.08.14 |
|---|---|
| 서버리스 사이트 스크린샷 찍기 (예전방식) (0) | 2019.08.12 |
| 서버리스 웹브라우저 한글폰트 적용하기 (0) | 2019.08.12 |
| 서버리스 AWS IAM Key 수명관리 (0) | 2019.08.07 |
| DynamoDB : Attribute name is a reserved keyword 해결방법 (0) | 2019.08.01 |
| DeletionPolicy 옵션 사용시 주의사항 (0) | 2019.07.31 |
| CloudFormation / Serverless Framework 삭제시 리소스 유지 (0) | 2019.07.30 |
| 네이버 블로그 파워링크 클릭 (0) | 2019.07.30 |


